Note - DDIA - Ch7 Transaction
Why we need transaction?
- Hardware fail
- Application fail
- Network interruption
- Multiple write at same time
- Read partially updated data
- Race condition between client
However, implementing a fault-tolerance machine costs too high so the need of transaction rise. Basic concept: All read and write are operation, if it success then commit, otherwise, abort/rollback.
more simpler because partial no partial fall and simplify the programming model for application accessing database. Application is free to ignore certain potential error because DB deal with it.
ACID
Database's ACID implementation various from one to another. Nowadays ACID implemented may not be as expected and become more marketing term.
Atomicity
Something cannot be broken down into smaller parts.
There are many different mean in other branch. For example, in multiple-threaded programming, it means no other thread can see half-finished thread's result. However, in ACID, atomicity is no mean for concurrency which is covered in isolation (AC"I"D).
Atomicity here, means when it fail, system can easily recover to previous state, perhaps abortability would have been better term.
Consistency
This word is terrible overloaded. In hasing, CAP, asynchronously replicant. The idea is certain statements about your data(invariant) should always be true.
It depend on application rather than on database and should be application's responsibility to define it. Database don't support this feature, or not support it well. For example, developer can manually modify data in database.
Isolation
If multiple read and write same part of database. There might be an race condition.
For example, both opA and opB want to read COUNT and add one. Currently , COUNT is 2, so the result could be 3 and 4.
Concurrent execution should be isolated to each other, or you can say serializability. But in reality , it is rarely used because of its performance penalty. Some database don't even implement it, but use weak isolation.
Durability
The purpose of database is to provide a safe place where data can be stored without fear of losing it.
| Single node | After write to SSD or hard disk. |
| Multiple node | After store to some number of nodes |
Durability guarantee, a database must wait until these write/replications are complete before reporting success.
However, perfect durability does NOT exist.
- Machine/disk is inaccessible until fix or transfer to another machine.
- Power outage or bug can crash every node. See reliability.
- Asynchronous replication, recent write may be lost if leader die.
- SSD/disk don't guarantee dead lock.
Single-Object and Multi-Object Operation
Multiple Object Operation
Transaction have multiple operations. For example,
| User 1 | Send mail to User 2 | Update unread counter | ||
| Database | ||||
| User 2 | Read mail from User 1 | Read unread counter |
There two problems in above graph.
- User 2 will see incorrect unread counter. This violate isolation principle where user 2 should not be able to read uncommitted transaction. This problem also called lost update where we lost the first update.
- If an error happened in update unread counter, database is hard to revert back. So it need atomicity.
Multiple-object transaction require some way of determining which read and write operations belong to the same transaction. In RDBMS, it typically done base on TCP connection. On any particular connection, everything between BEGIN, TRANSACTION and COMMIT should be considered as part of the same transaction.
Many non-relational database don't have such a way of grouping operations together. Even if there is a multi-object API, that doesn't mean it has transaction semantics: the command may succeed for some key and fails for others, leaving the database in a partially updated state.
Single Object Write
Storage engines almost universally aim to provide atomicity and isolation on level of single object.
| Atomicity | log for crash recovery |
| Isolation | lock |
Some more complex atomic operations like increment operation which remove the need of read-modify-write cycle, compare-and-set operation(only allows a write operation when the value has not been concurrently changed by someone else). However, they are very useful but not in the usual sense of the world as transaction.
The need of multi-object transactions
Many distributed database have abandoned multi-object transaction because it is hard to implement. Also high availability or performance is required.
There are some use cases in which single-object operation are sufficient. However, many other cases writes to several different object need to be coordinated.
- For RDB, foreign key need to be up to date.
- For document data model, need to update multiple documents after denormalized(usually copy data to multiple documents).
- Secondary index need multiple objection transaction to update.(A row of data might not exist in index before transaction committed)
Handling errors and aborts
Not all DB follow real ACID and abort all if fail.
DB with leaderless replication work much more on a "best effort", which will not abort all if fail.
Retry is good, but many framework don't implement it and some situation is not good for retry.
- Client need application-level deduplication mechanism. Otherwise if operation success then network fail on response, client will do false retry.
- Overload retrying the transaction. Can handle this by limit retry, and exponential back-off(dynamic waiting time).
- Only worth to retry temporary error.
- Transaction has side effect. Outside of DB may still have side effect even transaction is abort. For example, fail to send email but you don't want to re-send multiple times. It can be handled by two phase commit.
- Client process fails while retrying, any data it was trying to write to DB is lost.
Weak isolation levels
In theory, isolation should make your life easier by letting you pretend that no concurrency is happening.
Serializable isolation has a performance cost and many database don't want to pay the price. It therefore common for system to use weaker level isolation.
However, bug caused by weak isolation is not just a theoretical problem.
A popular comment is "if you want to deal with financial, use ACID." But nowadays, even popular RDBMS use weak isolation.
Dirty read/write
Read/write object when another transaction is not yet commit.
Having no dirty read/write cannot prevent race condition of some case. For example, you have series of transaction to update counter and if counter is 5 then add up 1.
| User 1 | Get counter //5 | Adds up counter //6 | ||
| Database | ||||
| User 2 | Get counter //5 | Adds up counter //7 |
The result should be 6 but we get 7.
Read committed
Read committed is a very popular isolation level. It is the default setting in the Oracle 11g. Most commonly, DB prevent dirty write by row level lock. How about dirty read? same method will have performance issue due to one write lock will block multiple read-only operation.
Now DB can remember two values. Old value and new value. give old value when locked and give new when no lock on data.
Snapshot isolation and repeatable read
How to make snapshot?
- Backup: Back up entire DB, however, write continue during backup, so data will be inconsistence. Observe DB between two transaction will return wrong result temporarily.
- Analytics: Just like query from data warehouse. However, these queries are likely to return nonsensical results if they observe parts of the db at different points in time.
The idea of snapshot isolation is that each transaction reads from a consistent snapshot of the DB. Why? it is very hard to reason about the meaning of a query if the data on which it operates is changing at the same time as the query is executing. but is it much easier to see a consistent snapshot of the database, frozen at a particular point in time.
It is a popular feature supported by many database, postgreSQL, MySQL, Oracle and others.
Principle: reader never block writers and vice versa.
Implementing snapshot isolation
Transaction may need to see different points of time, so it must keep several versions of snapshot(MVCC, multi-version concurrency control).
A typical approach is that read committed isolation(only remember old and new value) use separate snapshot for each query while snapshot isolation(usually MVCC) use the same snapshot for an entire transaction.
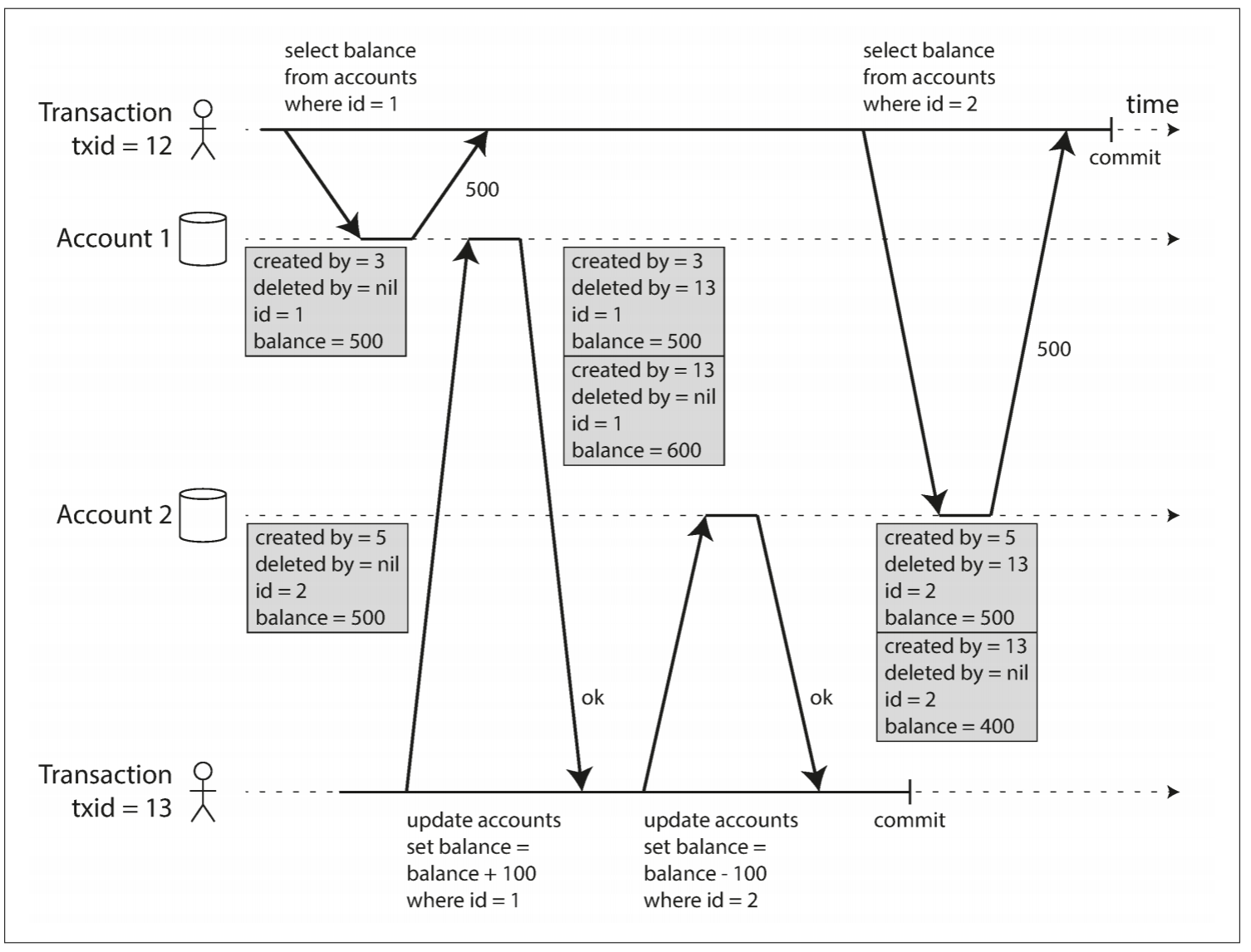
Image from the book of Design data-intensive application figure 7-7
From above graph, transaction 12 cannot see object created by transaction 13 so it still see 500 in account. Also, DB not really delete or change any data but keep all of these changes in stack. A deletion will ark for deletion and let garbage collection to delete it. An update is internally translate to delete and create.
Rules of MVCC:
- List all transaction in progress. Any write is ignored even if it is subsequently committed.
- Any write made by aborted transaction are ignored.
- Any write made by later transaction ID
- All other writers are visible to applications query
By never updating values in place but instead creating a new version every time a value is changed. the Database can provide a consistent snapshot while incurring only a small overhead.
Index and snapshot isolation
Need some way to handle performance issue for multi-version DB. For example, PostgreSQL has avoid index update if different version of same object can fit in same page. Another approach is used in couchDB, it use append-only approach which always make a copy up to root of tree. All transaction create a new root, but require background for grabage collection.
Other name of snapshot isolation
People use different name for snapshot isolation because it is not in SQL standard.
| Oracle | Serializable |
| PostgreSQL, mySQL | repeatable read |
Prevent Lost update
In above, we talked about how to guarantee a read-only transaction can see in the concurrent write. How about writing concurrently?
Atomic write operations
Many DB provide atomic update operation which remove the need of read-modify-write cycle. It usually the best solution if your code can expressed in terms of those operations. (write all operation in one SQL) But not all writes can easily do this. For example, update wiki page involve arbitrary text editing.
Usually implemented as an exclusive lock on the object until update is applied. This technique is sometimes known as cursor stability. Another option is to simply force all atomic operations to be executed on a single thread.
Unfortunately, object-realtional mapping framework make it easy to write code that performs unsafe read-write block instead if using atomic write operation provided by database.
Explicit locking
Let application to explicitly lock objects that are going to be update. for Example, multi-player game that every one can control same figure.
Automatically detect lost update
Allow execution in parallel, and if detect lost update, abort the transaction and force it retry read-modify-write cycle.
pros: efficiently in conjunction with snapshot isolation but not all DB has it. ex, mySQL don't has it.
Compare and set
If value is not the same as last read, retry operation. However, if query read from old snapshot, it my not detect change.
Conflicting resolution and replication
Lock and "Compare and set" doesn't work here because they assume there is always one updated replication. However, in multi-leader database, it is not the case. Instead, we have two options.
- Allow concurrent write and use application code and special data structure to resolve and merge these version after the fact. And it is a common approach.
- Atomic operation works well especially if they are commutative(order doesn't matter).
Last write win(LWW) is error prone in this case. Unfortunately, LWWW is the default in many replicated database.
Write skew and phantoms
Write skew, its neither dirty write nor lost update because two transaction update different object.
For example, it require at least one doctor is on-call. Currently Doctor A/B is both on-call.
- Doctor A/B check the sum of on-call person(2).
- Then update their on-call status to false.
- Then we have 0 on-call person.
In this case
- Atomic single-object operation doesn't help because it involves multiple objects.
- Automation detection of lost update doesn't help. Write skew is not automatically detected in major DB. Automatically preventing write skew require true serializable isolation.
- Some DB allow you define constrains. However, in this case, it need constrain that involves multiple objects. Most of DB don't have built in support for that. But you may be able to implement them with triggers or materialized views depending on DB.
- If you cannot use a Serializability isolation level. The second best option is explicitly lock the row.
Pattern of write skew
- Read
- Based on read result then decide next move
- Write
The order may change.
SELECT
WHERE
UPDATE; //"UPDATE" force DB to lock the row
Note, If now row return, then UPDATE cannot lock any row.
This effect where a write in one transaction changes the result of a search query in another transaction is called phantom. Snapshot isolation avoid phantom in read-only query but not read-write transaction.
Materializing conflict
One way to deal phantom(especially when row is not yet exist) is to materialize it. For example, booking meeting room. booking not yet exist, but we can create all combination of time slots and then lock it. (so the SQL above will return a row the lock it)
However, it is error-prone and ugly. It also let a concurrency control mechanism leak into the application data model. So this method should be the last option.
Serializability
We have some hard situation here.
- Isolation level are inconsistently implemented in different DB
- It is difficult to tell whether your code is safe to run at a particular isolation.
- There are no good tools to help us detect race conditions.
One simple solution is Serializability . Usually considered as strongest isolation level. It guarantee that if the transcations behave correctly when running individually, they continue to be correct when run concurrently. So DB prevent ALL possible race condition.
Three serialiazbility:
- Actual serial execution
- Two phase locking
- Optimistic concurrency control
Actual serial execution
The simplest way of avoiding concurrency problem is to remove them entirely.
Even though it seems obvious but it become feasible after 2007. Because
- Ram become cheap enough
- DB designer realized that OLTP transaction are usually short.
However, its throughput is limited to that of a single CPU core.
Encapsulating transactions in stored procedures
For example, booking a hotel, Can we make whole process into one procedure? Not a good idea. Human is too slow than DB will need to support huge number of concurrent transaction. On the web, it use interactive mode.
For this reason, single threaded serial transaction processing don't allow interactive multi-statement transactions. Because it spend too much time on network. Instead, application must submit entire transaction code to DB as stored procedure.
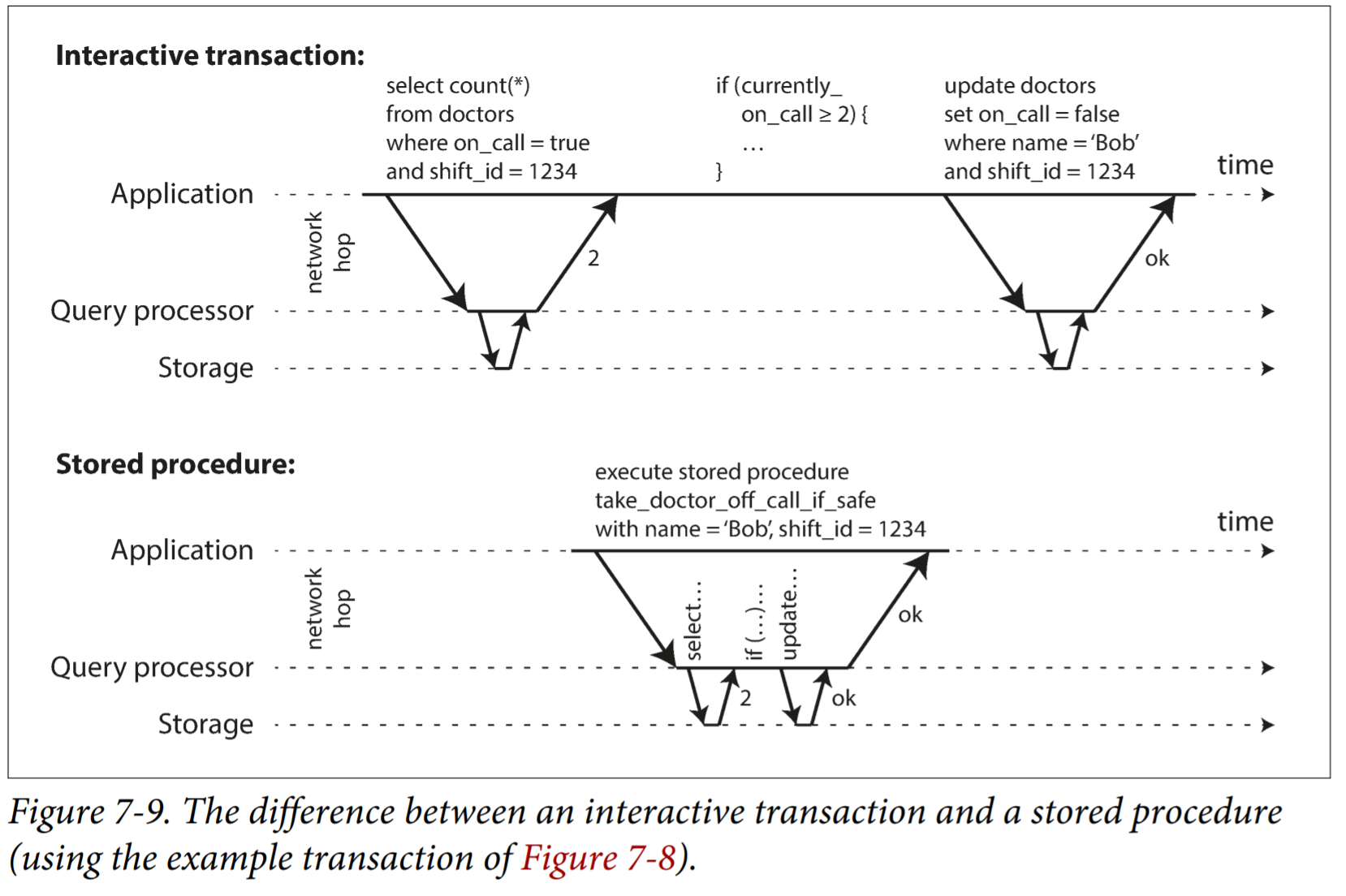
Pros and cons of stored procedure
Cons:
- Each DB vendor has its own language for stored procedure. These language haven't kept up with development in general-purpose programming language. So they look quite ugly.
- Code running in a DB is difficult to manage.
- A badly written stored procedure in a DB can cause much more trouble than equivalent badly written code in an application server.
Pros:
Issues above can be overcome. Morden implementation of stored procedure have abandoned PL/SQL and use general-purpose programming language. As they don't need to wait for I/O, they avoid overhead of other concurrency control of other concurrency control mechanisms. They can achieve quite good throughput on a single thread.
Replication
Procedure need to be deterministic(same result in different node).
Partitioning
Read-only transaction may execute else where, using snapshot isolation. But for applications with high write throughput, the single-threaded transaction processor can become a serious bottleneck.
If you can find a way to partition your dataset so that each read/write only happen in one partition then we can run concurrently.
However, for any transaction that needs to access multiple partition. The database must coordinating the all partitions it touch. That will have additional overhead, they are vastly slower than single-partition transaction.
Summary of serial execution
- Every transaction must be small and fast.
- It's limited to use cases where the actual dataset can fit in memory.
- Write throughput must be low enough to be handled on a single CPU core.
- Cross-partition transaction are possible. But hard to limit to the extent to which they can be used.
Two-phase Locking (2PL)
A more strict lock than snapshot isolation.
| Snapshot isoltion | Writer don't block readers, reader don't block writers |
| 2PL | Writer/reader block writers/readers |
Because of this, 2PL provide Serializability. It protects against all the race conditions, include lost update and write skew.
Implementation
- Lock can be either shared or exclusive.
- Reader can create shared lock, and serial can hold one share lock. So that other reader can read same object.
- Writer can create exclusive lock.
- After transaction, object must hold lock until commit.
- There are so many lock so it is easily to have deadlock. System will detect deadlock automatically and about one of them, aborted then retry.
Predicate locks
Lock with conditions. For example, book meeting room. It is ok to book same room in non-overlaping time slot. Predicate lock applies even to objects that do not yet exist in the database.
Index-range lock
Predicate lock do not perform well. That's why most 2PL actually implement index-range locking(next key locking). It is safe to simplify a predicate by making it match greater set of objects. For example, Booking a room from 12-1pm. You can attach a lock on time index around that.
If there is no suitable index. It fall back to shared lock on the entire table.
Serializable Snapshot Isolation(SSI)
Are Serializable isolation and good performance fundementally at odd with each other?
SSI is full serializable with little performance penalty. First described in 2008[1] now used in postgreSQL greater V9.1. FundationDB has use it across in different machine.
Pessimisitic versus optimistic concurrency control
2PL: A pessmistic method. It wiat until it is safe for transaction.
Serial execution: An extreme pessmisitic method. It is equivalent to each transaction have a exclusive lock.
Serializable snapshot isolation is an optimistic concurrency control. Instead of blocking off, execute anyway and abort transaction if conflicts. It performs badly if there are high contention(many transaction try to access same object. Retries make performance worse.)
On top of snapshot isolation, SSI add an algorithm for detecting serialization conflict among writes and determine which transaction to abort.
Decisions based on outdated premise
Outdated premise: The fact that was true at the beginning.
Under snapshot isolation, the result from the original query may no longer be up to date by the time the transaction commits. Take doctor on-call problem as example. In order to provide serializable isolation, the DB must detect situations in which a transaction may have acted on an outdated premise and abort the transaction in that case.
How to detect?
- Detecting reads of a stale MVCC object version(uncommitted write occurs before the read).
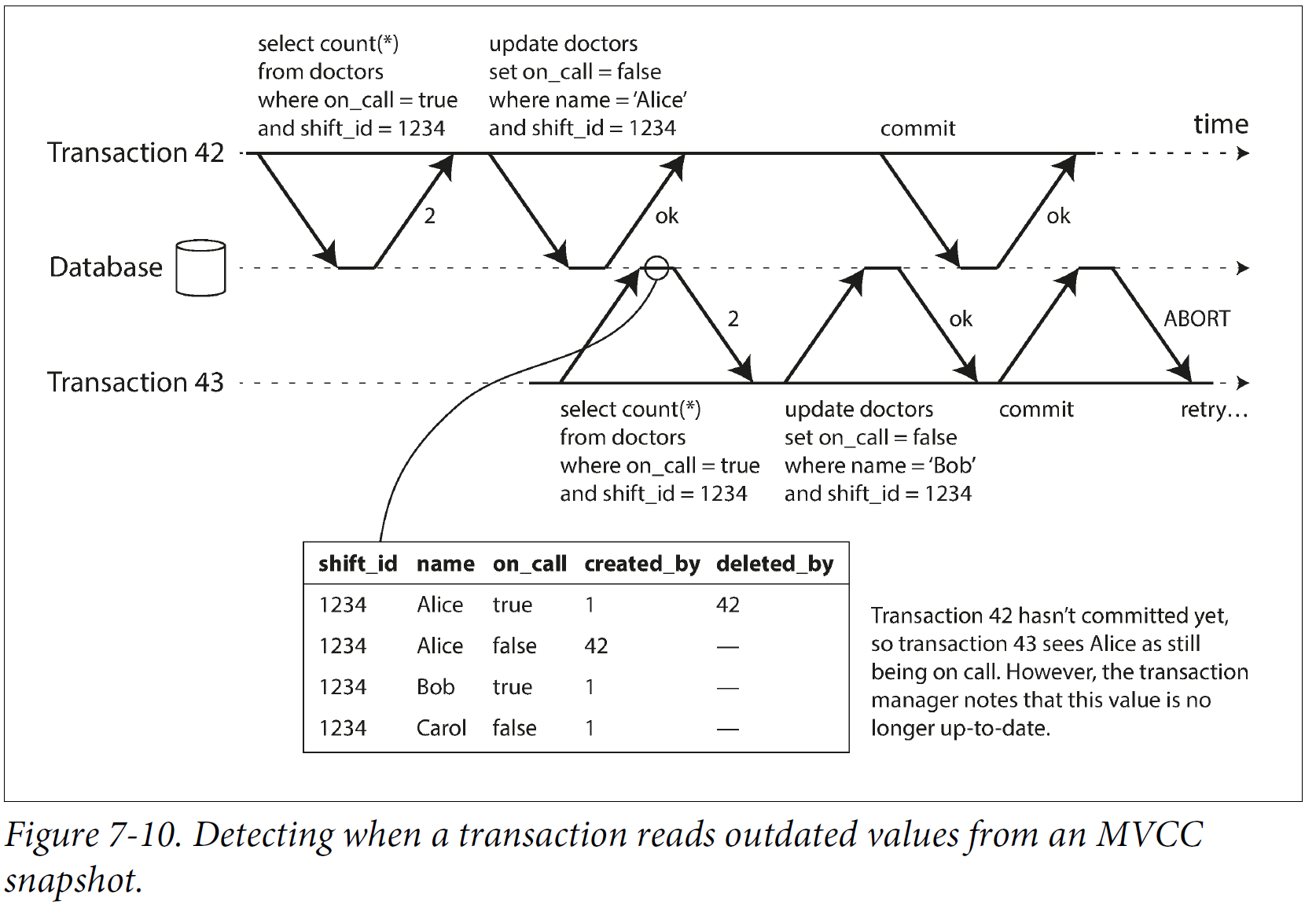
Transaction 42 is ignored until it is committed. After write, DB noted that value is no longer updated. After commit, transaction 43 is aborted.
- Detecting write that affects prior reads(write occurs after read, when another transaction modified data after it has been read).
Similar to index-range locking except SSI lock don't block other transactions.
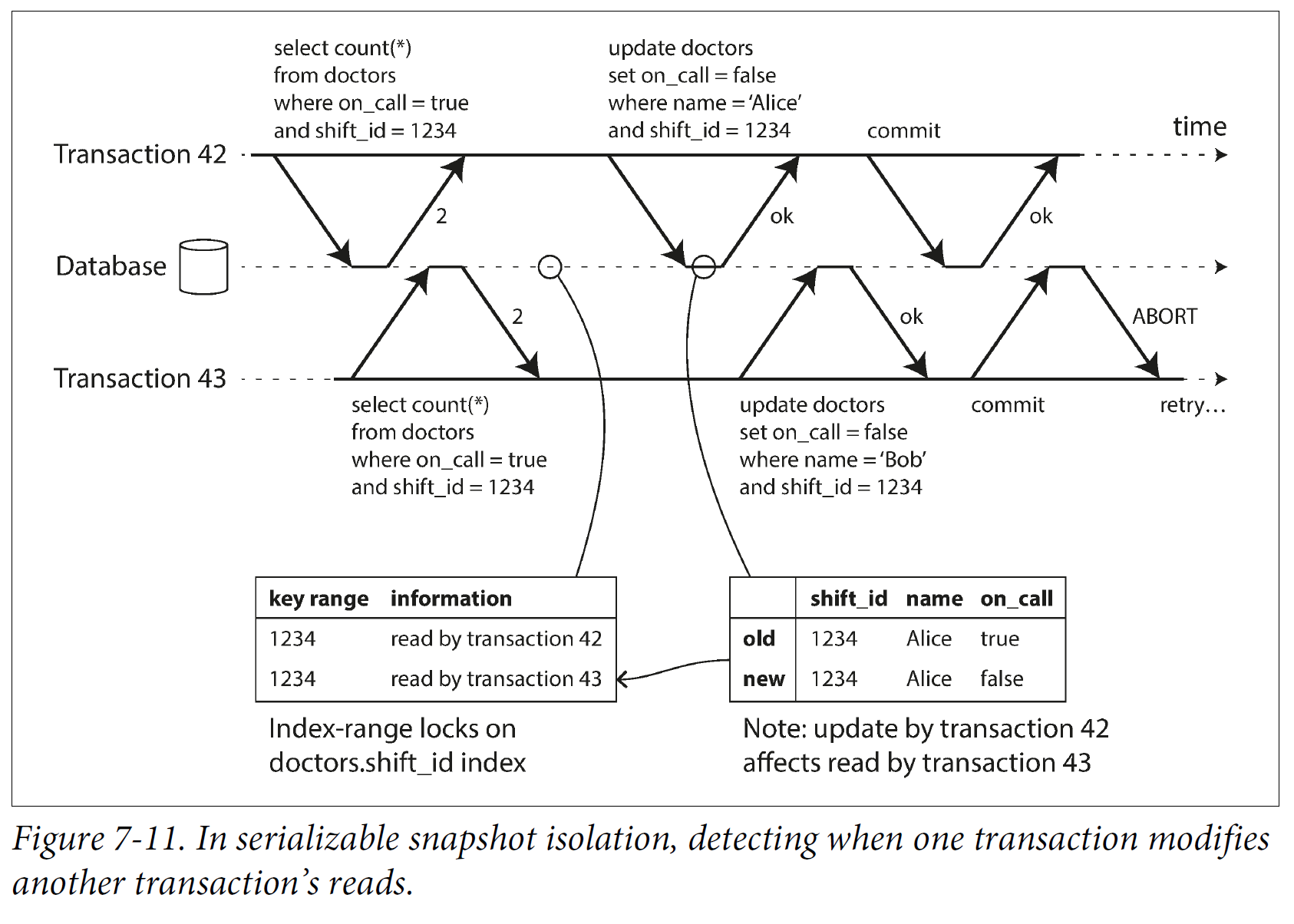
When transaction 42/43 look up for shift id 1234, DB find the index of 1234 if it exist and record 42/43 has read it. When transaction 42 udpate value, DB notify other transaction in its record that has read the value that value is no longer up to date. Transaction 43 will be aborted after 42 is committed.
Performance of serialized snapshot isolation
There's always a lot of trade off.
| Track all transaction | Precise, but slow and overhead |
| Not track all transaction | Faster, but some transaction will be aborted |
Compare to 2PL. The big advantage of serializable snapshot isolation is that one transaction doesn't need to be blocked and waiting for locks hold b other transaction. Read-only query can run on consistent snapshot without requiring any lock, which is very appealing for read-heavy workload.
Compare to seriazlized execution. Serialized snapshot isolation is not limit to the throughput of a single CPU core.
The rate of abort significantly affects the overall performance os SSI. So SSI requires that read-write transactions be fairly short. However, SSI is probably less sensible to slow transaction than 2PL locking or serial execution.
Reference:
DDIA
[1] Serializable isolation for snapshot database by Michael J. Cahill, Uwe rohm, and Alan Fekete at ACM International Conference on Management of Data