[Note] DDAI CH9
Consistency and consensus
one of the most import abstractions for distributed systems is consensus: that's it, getting all of the nodes to agree on something. Once you have an implementations of consensus, applications can use it for various purposes. For example, re-elect leader for single-leader replication.
Consistency guarantees
If you look at two replicated nodes at the same moment in time. You are likely to see different data on the two nodes because write requests arrive on different nodes. Most replicated databases provide at least eventual consistency.
However this is very weak guarantee, it doesn't say anything about when the replicas will converge. For example, you are note guarantee that you will see the value you just wrote, because the read may be routed to different replica. Eventual consistency is hard for application developer.
Linearizability
Wouldn't it be a lot simpler if the database could give the illusion that there is only one replica. This is the idea behind linearizability(also known as atomic consistency, strong consistency, immediate consistency, or external consistency). In other word, linearizability is a recency guarantee that guarantee the value read is the most recent, up-to-date value. For a system that is not linearizability might occurs users see different result from the same entry point. For example, game score.
Linearizability vs serializability
Serializabilityis an isolation property of transactions, where every transaction may read and write multiple objects. It guarantees that transaction behave the same as if they had executed in some serial order. And it is okay for that serial order to be different from the order in which transactions were actually run.Linearizabilityis a recency(most up-to-date) guarantee on reads and writes of a register.
And they are different.
Relying on linearizability
In what circumstances is linearizability useful?
Locking and leader election
A system that uses single-leader replication needs to ensure that there is indeed only one leader, not several (split brain). One way of electing a leader is to use a lock: every node that starts up tries to acquire the lock, and the one that succeeds becomes the leader(Chubby lock service). It must be linearizable: all nodes must agree which mode owns the lock; otherwise it is useless.
Constraints and uniqueness guarantees
It is common in databases: for example, a username or email address must uniquely identity one user. You can think of them acquiring a "lock" on their chosen username. It very similar to compare-and-set.
In database, a hard uniqueness constraint, such as the one you typically find in relational database, requires linerizability. Other kinds of constraints, such as foreign key or attribute constraints, can be implemented without requiring linearizability.
Cross channel timing dependencies
It can solve game score problem that tow guy might see different score from the same game since not all user are seeing the most up-to-date score.
In a more complex example of image resizer,
Upload image -> web server -> store full-size image -> file storage <----------|
|-> send message to message queue -> image resizer <-|
If there is no linearizability, there could be a race condition like image resizer is faster than storage so could'nt find the image.
Implementing lineariable systems
The simplest answer would be to really only use a single copy of the data. However, that approach would not be able to tolerate faults.
-
Single-leader replication (potentially linearizable)
It's potentially linearizable. However, not every single-leader database is a actually linearizable, either by design(e.g. use snapshot isolation) or due to concurrency bugs(MongoDB stale read).Using the leader for reads relies on the assumption that you know for sure who the leader is. It is possible that a node to think that it is the leader, when in fact it is not. With asynchronous replication, fail over may even lose committed writes due to old leader failed when not all the results have been received.
-
Consensus algorithms (linearizable)
Consensus protocols contain measures to prevent split brain and stale replicas. Because of this consensus algorithms can implement linearizable storage safely. -
Multi-leader replication (not linearizable)
System with multi-leader replication are generally not linearizable, because they concurrently process writes on multiple nodes and asynchronously replicate them to other nodes. For this reason, they can produce conflicting writes that require resolution. -
Leaderless replication (probably of linearizable)
For systems with leaderless replication (Dynamo-style), people sometimes claim that you can obtain "strong consistency" by requiring quorum reads and writes(w+r > n)."Last write wins" conflict resolution methods based on time-of-day clocks(e.g. Cassandra) are almost certainly nonlinearizable, because clock timestamps cannot be guaranteed to be consistent with actual event ordering due to clock skew.
Linearizability and quorums
- Quorums: if there are n replicas, every write must be confirmed by w nodes to be considered successful, and we must query at least r nodes for each read. As long as w + r > n, we expect to get an up-to-date value when reading, because at least one of the r nodes we're reading from must be up-to-date.
Although strict quorumr reads and writes should be linearizable in Dynamo-style model. However, reads can happens before all the writes finished which will break the linearizable.
Interestingly, it is possible to make Dynamo-style quorums linearizable at the cost of reduced performance: a reader must perform read repair synchronously, before returning results to the application, and write must read the latest state of a quorum of nodes before sending its writes.
The cost of linearizability
If some replicas are disconnected from the other replicas due to a network problem, then some replicas cannot process requests while they are disconnected: they must either wait until the network problem is fixed, or return an error. Either way, they become unavailable.
CAP theorem
Consistency, Availability, Partition tolerance. Pick 2 out of 3. However, this is misleading. Because network partition aren't something you have choice. When network is working, you can choose between either linearizability or total availability. When network fault occurs, you have to choose between either linearizability or total availability. Thus CAP would be either Consistent or Available when partitioned.
CAP does not help us understand systems better, so CAP is best avoided.
Linearizability and network delays
Although linearizability is a useful guarantee, surprisingly few systems are actually linearizable in practice.
The reason for dropping linearizability is performance. Can't we maybe find a more efficient implementation of linearizable storage?
It seems answer is no. paper prove that if you want linearizability, the response time of read and write requests is at least proportional to the uncertainty of delays in the network. This trade-off is important for latency-sensitive systems.
Ordering guarantees
The causal order is not a total order
A total order allow any two elements to be compared, so if you have two elements you can always say which one is greater. Linearizability have total order of operations. We can always say which one happened first. Causality is partial order.This means some operations are ordered with respect to each other but some are incomparable
Therefore, according to this definition, there are no concurrent operations in a linearizable datastore: there must be a single timeline along which all operations are totally ordered.
Git version is casuality, your commit must happened after another.
Linearizability is stronger than causal consistency
Any system that is linearizable will preserve causality correctly. Linearizability ensures that causality is automatically preserved without the system having to do anything special.
In fact, causal consistency is the strongest possible consistency model that does not slow down due to networks delays, and remains available in the face of network failures.
In many cases, system that appear to require linearizability in fact only really require causal consistency. Researchers are exploring new kinds of databases that preserve causality. these research is quite recent, not much of it has yet made its way into production system. and there are still challenges to be overcome.
Sequence number ordering
Although causality is an important theoretical concept, actually keeping track of all causal dependencies can become impractical. However, a timestamp need not come from a time-of-day clock (unreliable). It can instead come from a logical clock, which is an algorithm to generate a sequence of numbers to identify operations.
Noncausal sequence number generators
If you are not using single leader (perhaps because you are using a multi-leader of leader-less), it is less clear how to generate sequence numbers for operations.
These three options all perform better and are more scalable than pushing all operations through a single leader that increments a counter. However, the sequence numbers they generate are not consistent with causality.
- Each node can generate its own independent set of sequence numbers. And you can reserve some bits to contain a unique node identifier.
- Some node's counter may behind another.
- Attach timestamp from a time-of-day clock (physical clock) to each operation. Such timestamps are not sequential, but if they have sufficiently high resolution, they might be sufficient to totally order operations. This is used in last write win.
- Clock is not reliable and may be changed when next sync.
- Preallocate blocks of sequence numbers.
- Same as first one
Lamport timestamps
Lamport timestamp is a simple method for generating sequence numbers that is consistent with causality.
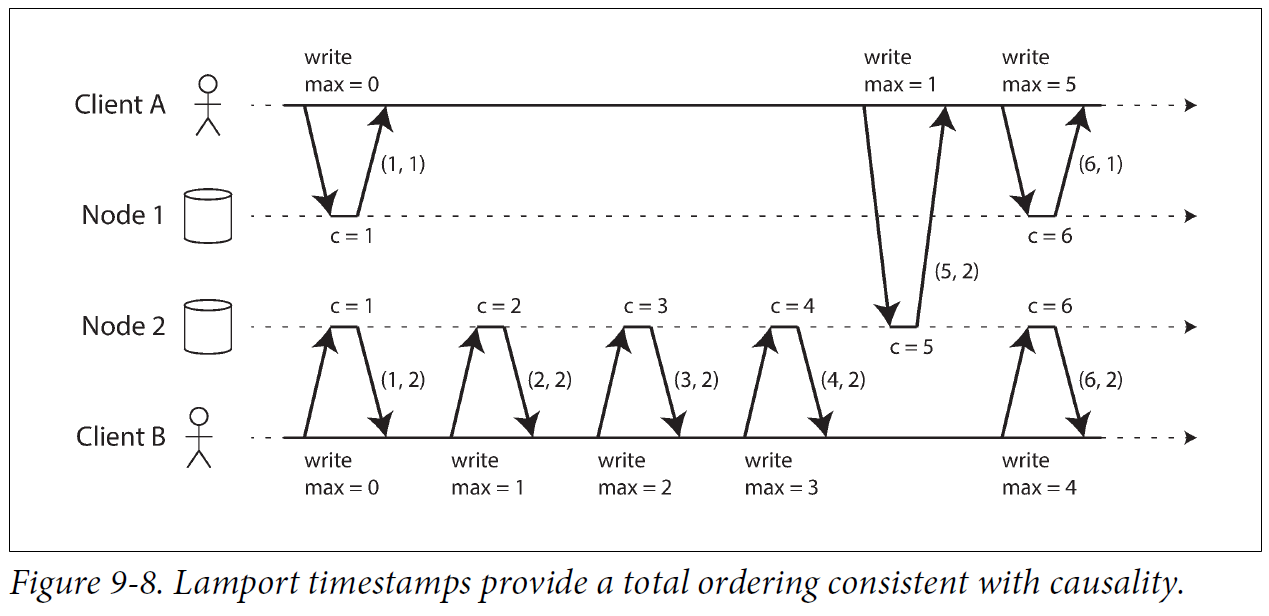
(Image from Designing Data-Intensive Application)
Difference between lamport timestamp and version vectors.
- Version vector: Detect concurrent and dependency of operation.
- Lamport: Enforce total ordering and more compact.
Timestamp ordering is not sufficient
It's still not quite sufficient to solve many common problems in distributed systems. The problem of Lamport is that it decide only after it collect all the data. For example, if you want to check if username is unique, it need to wait ti talk to all the nodes.
Conclusion: You also need to know when that order is finalized. If you have an operation to create a username, and you are sure that no other node can insert a claim for the same username ahead of your operation in the total order.
Total order broadcast
You can decide total order of operations by choosing one node as the leader. But th problem is how to scale the system if the throughput is greater than a single leader can handle.
Informally, it requires two safety properties always be satisfied even with network fault. Reliable delivery (No message lost) and totally ordered delivery(delivery in order for all nodes.) Also, a node is not allowed to retroactively insert a message into an earlier position in the order if subsequent message have already been delivered.
It is useful to create a log service and lock service.
Implementing linearizable storage using total order broadcast
You can build linearizable storage on top of it. For example, you can ensure that usernames uniquely identify user accounts.
- Append a message to the log with the username.
- Read the log and wait for message you appended to be delivered back to you
- Check for any message claim same username before you.
But method above do not guarantee linearizable read. There are few options for read linearizable.
- Append message and read log when it is back. (Quorum read in etcd)
- If the log allows you to fetch the position of the latest log message in a linearizable way, you can query the position, wait for all entries up to that position to e delivered to you, and perform the read. (ZooKeeper's sync() operation)
- You can make your read from a replica that is synchronously updated on writes, and it thus sure to be up to date. (Chain replication)
Implementing total order broadcast using linearizable storage
The easiest way is to assume you have a linearizable register that stores an integer ind that has an atomic increment-and-get operation. Algorithm is simple, attach an ID from register and so recipient will receive message according to the ID.
Note this is different from Lamport timestamps. linearizable won't have increment number gap while Lamport might have it.
How hard is it? This question will eventually leads you to consensus problem.
Distributed transactions and consensus
There are a number of situations in which it is important for nodes to agree.
- Leader election
- Atomic commit: To prevent node fault, and all the node have to agree on the outcome.
The impossibility of consensus
FLP result(Fischer, Lynch, and Paterson): there is no algorithm that is always able to reach consensus if there is a risk that a node may crash. It is important theoretical research, but distributed systems can usually achieve consensus in practice.
Atomic commit
For transactions that execute at a single database node, atomicity is commonly implemented by the storage engine.
For single node: Use write ahead log(write to disc first and then commit to log) so we can restore to proper state of node during crash.
Two phase commit (2PC)
For multi-node: It is not sufficient to simply send a commit request to all of the nodes and independently commit the transaction on each one. Some cases might fail the atomicity guarantee, some nodes success and some nodes fail, commit request lost in network, node crash before commit record.
2PC is an algorithm for achieving atomic transaction commit across multiple nodes.
Note: 2PC is different from 2PL(two-phase locking) where it is used to make sure multiple object read and write.
Example:
- Coordinator write to database 1
- Coordinator write to database 2
- Phase 1: ask if all the databases are ready to commit, abort transaction if anyone of them replies no.
- Phase 2: ask all the databases to commit. This will keep trying until all node commit or coordinate recover.
If coordinator fails at phase 2, participant can communicate with each other and vote for outcome. However, it is not 2PC's protocol.
Three phase commit
Also called blocking atomic commit protocol due to that 2PC can become stuck waiting for the coordinator to recover. In theory, it is possible to make an atomic commit protocol nonblocking, but in partical it is not that straightforward.
However, 3PC assumes a network with bounded delay and nodes with bounded response times; in most practical systems with unbounded network delay and process pauses.
Distributed transactions in practice
On the other hand, they are seen as providing an important safety guarantee that would be hard to achieve otherwise; on the other hand, they are criticized for causing operational problems, killing performance, and promising more than they can deliver.
Two different type of distributed transactions are often conflated.
Database-internal distributed transactions: All the nodes runs the same database
Heterogeneous distributed transactions: There are two or more different technologies: for example, two databases from different vendors, message brokers.
Exactly-once message processing
A message from a message queue can be acknowledged as processed if and only if the database transaction for processing the message was successfully committed. This is only possible if all the systems affected by the transaction are able to use the same atomic commit protocol.
XA transactions
Extended Architecture is a standard for implementing two phase commit across heterogeneous technologies. XA is not a protocol but a C API interface. but it is widely adopted in many other places like JDBC. XA assumes that your application use a network driver or client library to communicate with the participant databases or messaging service.
If the application process crashes, or the machine on which the application is running dies, the coordinator goes with it. Prepared bu uncommitted transactions are then stuck in doubt. Database server cannot contact the coordinator directly since all communication must go via its client library.
Participants stuck in doubt because of lock. They cannot proceed until lock is released.
In theory, coordinator crashes can recover its state from the log and resolve any in-doubt transactions. However, in practical, orphaned in-doubt transactions do occurs(due to log lost or something else). The only way out for this is for an administrator to manually decide whether to commit or roll back the transaction.
Fault tolerant consensus
Consensus must satisfy the following properties.
- Uniform agreement: No two nodes decide differently
- Integrity: No node decide twice.
- Validity: If a node decides a value v, then v was proposed by some node.
- Termination: Every node that does not crash eventually decides some value. A crashed node will be considered as lost forever.
Consensus algorithm and total order broadcast
The best-known fault-tolerant consensus algorithm are Viewstampede Replication (VSR).There are a quite a few similarities between these algorithms, but they are not the same.
Most of the algorithm actually don't use the method here (propose a value, integrity, validity, and termination). Instead, they decide on a sequence of values,which makes them total order broadcast algorithms.
Viewstamped Replication implement total order broadcast directly, because that is more efficient than doing repeated rounds of one-value-at-a-time consensus.
Single-leader replication and consensus
We need to choose a leader by consensus. Manually select a leader by human can be considered to be a kind of consensus.
Epoch numbering and quorums
- Vote to choose a leader.
- Vote on leader's proposal.
The quorums for those two votes must overlap. The second vote also reveals weather there is any higher-numbered epoch (other leader that can make conflict decision)
It looks very similar to 2PC. The biggest differences are that in 2PC the coordinator is not elected, and 2PC requires a "yes" from every participant.
Limitations of consensus
Consensus isn't used everywhere because the benefit cone at a cost.
The process by which nodes vote on proposals before they are decide is a kind of synchronous replication. And many people choose to accept the risk for the sake of better performance.
Consensus require a minimal nodes to participate in vote. If a traffic failure cut off some nodes and might block the voting system if not enough node present.
Consensus generally rely on timeouts to detect failed node. In environment with high network delays, it might falsely hold leader election frequently and harm the performance. Thus consensus is very sensitive to network problems.
Membership and coordination services
Projects like ZooKeeper or etcd are often described as "distributed key-value store" or "coordination and configuration services". Although it is rarely used them directly, it is often use them indirectly.
ZooKeeper implements not only total order broadcast (and hence consensus), but also an interesting set of other features that turn out to be particularly useful when building distributed systems.
- Linearizable atomic operations:
If several nodes concurrently try to perform the same operation, consensus protocol guarantees that the operation will be atomic and linearizable. - Total ordering of operations:
ZooKeeper providers fencing token to protect object in lock or lease by totally ordering all operations and giving each operation a monotonically increasing transaction ID. - Failure detection:
Clients maintain a long-living session on ZooKeeper servers and periodically exchange heartbeats to check that the other node is still alive. ZooKeeper declares the node to be dead when exchange timeout. - change notifications
Clients can subscribe to changes (like new client join or client disappear)
Only the linearizable atomic operations use consensus but these four features make ZooKeeper popular.
Allocating work to nodes
Some example in which the Zookeeper/Chubby model works well.
- Choose a leader among several instances of a process or service.
- Job scheduler and similar stateful system.
- Decide which partition to assign to which node.
- Rebalance the load when new node join.
These kinds of task can be achieved using atomic operations, ephemeral nodes, and notifications in ZooKeeper. It's not easy but still better than attempting to implement the necessary consensus algorithms from scratch.
Service discovery
Zookeeper, etcd, and Consul are also often used for service discovery. To find out which IP address you need to connect to in order to reach a particular service. Although service discovery does not require consensus, leader election does. Thus if your consensus system already knows who the leader is, the it can make sense to also use that information to help other services discover who the leader is.
Membership services
A membership service determines which nodes are currently active and live members of a cluster. We can use consensus to determine the membership of a node. For example, choosing a leader could simply mean choosing the lowest-numbered among the current members. But this won't work if there is a divergent opinions on who the current members are.